CS 스터디
챕터 16: 슈퍼 컴퓨터부터 사물 인터넷 까지
슈퍼컴퓨터
슈퍼컴퓨터는 “당대터들 중에서 가장 빠른 계산 성능을 갖는 컴퓨터들” 이라고 정의된다. 이와 같은 정의는 매우 상대적인 개념으로, 한 때는 슈퍼컴퓨터로 불리던 컴퓨터들이 컴퓨터 성능의 발전에 따라 미래에는 일반적인 고성능 컴퓨터 정도로 지칭될 수 있다는 것을 의미한다.
슈퍼컴퓨터는 과학기술 연산을 비롯한 다양한 분야에 사용 되는 고속 컴퓨터다. 보통 많은 수의 프로세서와 대량의 메모리를 사용한다. 사용되는 프로세서 자체도 종래 프로세서보다 특정 종류의 데이터를 훨씬 빨리 처리하는 명령어로 구성 되어 있다.
사물 인터넷(IOT, Internet of Things)
사람, 사물, 공간, 데이터 등의 모든 것이 센서와 토인 기능을 내장하여 인터넷에 연결하는 기술인 무선 통신기술을 통해 서로 연결되어 정보가 생성, 수집, 공유, 활용되는 초연결 인터넷.
인터넷으로 연결된 사물들이 데이터를 주고받아 스스로 분석하고 학습한 정보를 사용자에게 제공하거나 사용자가 이를 원격으로 제어할 수 있도록 하는 것.
네트워크에 연결된 온도 조절장치, 보안 카메라, 스마트 조명, 음성 인식 장치등을 포함한 수많은 기기도 다른 컴퓨터들 처럼 "프로세서" 를 기반으로 작동한다.
슈퍼 컴퓨터의 용도
군사 - 이지스함
- 다수의 목표물에 대한 동시교전 능력과 무기 관제, 탄도 계산 등을 위해 “함”마다 슈퍼컴퓨터가 들어간다.
기상청 - 날씨예측
- 상술한 지구과학, 물리학, 수학 등 모든 분야를 망라한 미분방정식을 천만개 이상의 격자점에서 계산한다. 한국과 전 세계의 기상청과 민간 기상 예보업체에서 이를 위한 슈퍼컴퓨터를 사용하고 있다.
시뮬레이션 - 가상핵실험
- 2차 전쟁 시대가 끝나 더이상 핵실험을 하기 힘들어졌다. 이때부터 슈퍼 컴퓨터를 이용한 가상 핵실험이 유행이 되었다
시뮬레이션 - 과학연산
- 지구과학: 대규모 시뮬레이션
- 생물학: 단백질, dna등 고분자 분석, 뉴련과 뇌 신경망 시뮬레이션, 세포 시뮬레이션, 생태 시뮬레이션
- 천문학: 전파 망원경 신호 처리, 대규모 은하 시뮬레이션 혹은 우주 거대 구조 시뮬레이션
- 생물학: 단백질, DNA 등 고분자 분석, 뉴런과 뇌 신경망 시뮬레이션, 세포 시뮬레이션, 생태 시뮬레이션
- 이 외의 많은 분야에서 사용되고있다.
분산 시스템
인터넷에 연결된 여러 컴퓨터들의 처리능력을 이용하여 거대한 계산문제를 해결하는 분산처리 모델.
분산 시스템은 고유하는 공동의 목표를 달성하기 위해 여러 개의 개별 컴퓨팅 노드에서 컴퓨팅 리소스를 활용하는 컴퓨터 프로그램의 모음
분산 시스템의 특징
- 리소스 공유 - 분산 시스템은 하드웨어, 소프트웨어 또는 데이터를 공유 할 수 있음
- 확장성 - 컴퓨팅 및 처리 용량은 추가 시스템으로 확장할 때 필요에 따라 확장할 수 있음
- 오류 감지 - 장애를 더 쉽게 감지 할 수 있음
- 투명성 - 노드는 시스템의 다른 노드에 액세스하고 통신 할 수 있음
중앙집중식 시스템 vs 분산 시스템
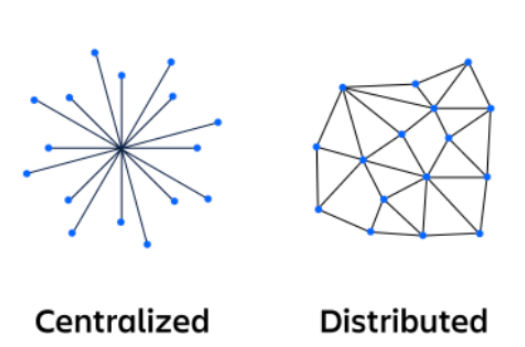
- 중앙 집중식 컴퓨팅 시스템에서는 하나의 컴퓨터가 모든 컴퓨팅을 한 곳에서 수행한다.
- 중앙 집중식 시스템과 분산 시스템의 주요 차이점은 시스템 노드 간의 통신 패턴이다.
- 중앙 집중식 시스템의 상태는 클라이언트가 맞춤형 방식으로 액세스하는 중앙 노드 내에 포함된다.
- 중앙 집중식 시스템의 노드는 모두 중앙 노드에 액세스하므로 네트워크가 혼잡해지고 느려질 수 있다.
- 중앙 집중식 시스템에는 단일 장애 지점이 있지만 분산 시스템에는 단일 장애 지점이 없다.
분산 컴퓨팅의 활용
대규모 과학 모델링.
- 환경 모델에는 최종 모델에 포함하기 전에 단일 컴퓨터가 하나씩 해결해야하는 많은 변수가있을 수 있습니다. 분산 컴퓨팅을 사용하면 이러한 각 변수를 다른 시스템으로 파싱 할 수 있으며 대부분의 경우 실시간으로 결과를 훨씬 빠르게 생성 할 수 있습니다.
산업 제어 시스템
- 산업제어 시스템은 매우 직접적인 방식으로 분산 컴퓨팅을 사용한다.이러한 컴퓨터 클러스터는 두 가지 유형의 시스템을 실시간으로 모두 감독하여 결과를 서로 작업자에게 지속적으로 보고합니다. 산업 공정에 오작동 또는 고장이 발생하면 네트워크는 오작동이 발생한 위치를 바로 찾아 내고 수리 될 때까지 주변을 라우팅 할 수 있습니다. 같은 방법으로 항공기 제어 시스템은 공항에서 교통 패턴, 궤적 및 클리어 활주로를 신속하게 파악하여 공항에서 안전하고 효율적으로 운영 할 수있을뿐만 아니라 날씨 중단으로 인한 문제 지역을 여행 할 수 있습니다.
항공기 제어 시스템
- 항공기 제어 시스템은 공항에서 교통 패턴, 궤적 및 클리어 활주로를 신속하게 파악하여 공항에서 안전하고 효율적으로 운영 할 수있을뿐만 아니라 날씨 중단으로 인한 문제 지역을 여행 할 수 있습니다.
알고리즘
정렬(2)
빠른 정렬 (Quick Sort)
def quicksort(lst, start, end):
def partition(part, ps, pe):
pivot = part[pe]
i = ps - 1
for j in range(ps, pe):
if part[j] <= pivot:
i += 1
part[i], part[j] = part[j], part[i]
part[i + 1], part[pe] = part[pe], part[i + 1]
return i + 1
if start >= end:
return None
p = partition(lst, start, end)
quicksort(lst, start, p - 1)
quicksort(lst, p + 1, end)
return lst
병합 정렬 (Merge Sort)
def merge(arr1, arr2):
result = []
i = j = 0
while i < len(arr1) and j < len(arr2):
if arr1[i] < arr2[j]:
result.append(arr1[i])
i += 1
else:
result.append(arr2[j])
j += 1
while i < len(arr1):
result.append(arr1[i])
i += 1
while j < len(arr2):
result.append(arr2[j])
j += 1
return result
def mergesort(lst):
if len(lst) <= 1:
return lst
mid = len(lst) // 2
L = lst[:mid]
R = lst[mid:]
return merge(mergesort(L), mergesort(R))
힙 정렬 (Heap Sort)
class BinaryMinHeap:
def __init__(self):
# 계산 편의를 위해 0이 아닌 1번째 인덱스부터 사용한다.
self.items = [None]
def __len__(self):
# len() 연산을 가능하게 하는 매직 메서드 덮어쓰기(Override).
return len(self.items) - 1
def _percolate_up(self):
# percolate: 스며들다.
cur = len(self)
# left 라면 2*cur, right 라면 2*cur + 1 이므로 parent 는 항상 cur // 2
parent = cur // 2
while parent > 0:
if self.items[cur] < self.items[parent]:
self.items[cur], self.items[parent] = self.items[parent], self.items[cur]
cur = parent
parent = cur // 2
def _percolate_down(self, cur):
smallest = cur
left = 2 * cur
right = 2 * cur + 1
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
if smallest != cur:
self.items[cur], self.items[smallest] = self.items[smallest], self.items[cur]
self._percolate_down(smallest)
def insert(self, k):
self.items.append(k)
self._percolate_up()
def extract(self):
if len(self) < 1:
return None
root = self.items[1]
self.items[1] = self.items[-1]
self.items.pop()
self._percolate_down(1)
return root
def sorted_by_heap(lst):
maxheap = BinaryMaxHeap()
for elem in lst:
maxheap.insert(elem)
desc = [maxheap.extract() for _ in range(len(lst))]
return list(reversed(desc))

알고리즘 문제
Sort Colors,
Merge Two Sorted Lists,
K Closest Points to Origin,
Sort List,
Merge Intervals,
Valid Anagram,
좌표 정렬하기 - 백준,
좌표 정렬하기 2 - 백준,
단어 정렬 - 백준,
나이순 정렬 - 백준,
수 정렬하기 2 - 백준.
PS 스터디(정렬)
일반 정렬
내림차순 정렬은 다음과 같이 sort 함수를 이용해 오름차순으로 정렬한 뒤 리스트를 뒤집는 방식으로 구현해볼 수도 있다.
arr = [12, 41, 37, 81, 19, 25, 60, 20]
arr.sort()
arr = arr[::-1] # reversed array
print(arr) #[81, 60, 41, 37, 25, 20, 19, 12]위의 경우에서는 리스트를 뒤집기 위해 slicing을 사용했지만, 리스트를 뒤집어 주는 reversed라는 함수도 있다. 이 함수를 사용하면 다음과 같이 구현이 가능하지만, reversed를 사용시 다시 list로 감싸줘야 뒤집어진 list를 얻어낼 수 있다.
arr = [12, 41, 37, 81, 19, 25, 60, 20]
arr.sort()
arr = list(reversed(arr)) # reversed array
print(arr) #[81, 60, 41, 37, 25, 20, 19, 12]문자열에 숫자 정렬에 이용했던 sort() 함수를 이용해보면, 문자열은 sort라는 함수를 사용할 수 없다는 에러를 만나게 된다.
string = "banana"
string.sort()
>> AttributeError: 'str' object has no attribute 'sortsort 함수를 쓰기 위해서는 list를 만들어 사용해야 하기 때문에, 문자열을 각 문자를 원소로 갖는 list로 변환 후 sort 함수를 이용하면 정렬이 가능하다. 정렬 이후에 다시 list를 join 함수를 이용해 문자열로 만들어 주면 해결된다.
string = "banana"
arr = list(string)
arr.sort()
print(arr) # ['a', 'a', 'a', 'b', 'n', 'n']
sorted_str = ''.join(arr)
print(sorted_str) # aaabnnsorted 함수의 경우에는, 문자열을 함수 인자로 넣더라도, 이를 성공적으로 정렬해줍니다. 다만, 결과물이 list로 나오기 때문에 다시 join 함수를 이용해 문자열을 만들어 준다.
string = "banana"
sorted_arr = sorted(string)
print(sorted_arr) # ['a', 'a', 'a', 'b', 'n', 'n']
sorted_str = ''.join(sorted_arr)
print(sorted_str) # aaabnn객체
두 학생의 국,영,수 점수 (90, 80, 90), (80, 70, 60) 를 코드로 옮길때 가장간단한 방법은 다음과 같다.
kor1, eng1, math1 = 90, 80, 90
kor2, eng2, math2 = 80, 70, 60하지만 (국,영,수) 가 한 학생의 점수라는 연관성을 보여주기엔 부족하다. 그래서 우리는 학생을 지정하는 새로운 형태(Class) 를 하나 정의하고, 그 형태를 이루기 위한 요소(멤버 변수) 로 (국,영,수) 를 정의할수 있다.
class Student:
def __init__(self, kor, eng, math):
self.kor = kor
self.eng = eng
self.math = math__init__ 함수는 이 Student 클래스의 형태를 정의해주는 생성자 라고 불리는 함수이다. 항상 self를 첫 번째 인자로 넣어주고, self는 학생을 지칭한다. 인자로 넘어오는 kor, eng, math는 현재 학생의 kor, eng, math 라는 값이 되아야 하기 때문에 그 값을 대입해 주는 식으로 코드를 작성하며, 이때 이러한 kor, eng, math 값을 멤버 변수라고 부른다.
클래스를 사용하려면 다음과 같은 코드를 작성해 볼 수 있다. Student를 함수 호출을 할 때 처럼 사용하며, __init__ 함수에 self 다음오는 인자 순서대로 값을 적어주면 각각의 멤버 변수 값을 갖는 하나의 학생 객체 (instance) 를 만들어 내게 된다. 멤버 변수값의 조회는 다음과 같이 할 수 있다.
student1 = Student(90, 80, 90)
print(student1.kor) # 90
print(student1.eng) # 80
print(student1.math) # 90
class Student:
def __init__(self, kor, eng, math):
self.k = kor
self.e = eng
self.m = math
student1 = Student(90, 80, 90)
print(student1.k) # 90
print(student1.e) # 80
print(student1.m) # 90다음과 같은 방법으로 객체 리스트를 만들어 보는것도 유용하다.
class Student:
def __init__(self, kor, eng, math):
self.kor = kor
self.eng = eng
self.math = math
students = [
Student(90, 80, 90), # 첫 번째 학생
Student(20, 80, 80), # 두 번째 학생
Student(90, 30, 60), # 세 번째 학생
Student(60, 10, 50), # 네 번째 학생
Student(80, 20, 10), # 다섯 번째 학생
]
student3 = students[2] # 세 번째 학생 정보
print(student3.kor) # 90
print(student3.eng) # 30
print(student3.math) # 60
# list comprehension 을 사용한 경우
class Student:
def __init__(self, kor=0, eng=0, math=0):
self.kor = kor
self.eng = eng
self.math = math
students = [Student() for _ in range(5)] # 5명의 학생 추가
student3 = students[2] # 세 번째 학생 정보
print(student3.kor) # 0
print(student3.eng) # 0
print(student3.math) # 0튜플(Tuple)
class를 만드는 방법 외에도 튜플을 이용하여 문제를 해결할 수도 있다. 튜플은 리스트와 비슷하지만 크게 2가지 차이점이 있다.
- 튜플에 들어있는 값은 수정할 수 없다.
- 튜플에 추가 원소를 넣거나 기존 원소를 제거하는것은 불가능 하다.
즉, 튜플은 immutable 한데, 우리가 리스트 대신 튜플을 사용하는 주된이유는 주로 패킹과 언패킹이다.
다음과 같은 코드를 살펴보자.
def hello():
return 1, 2
a, b = hello() # 함수로 부터 (1,2) 라는 tuple을 return 받는다.
print(a, b, a + b)a는 1 을 b는 2라는 값을 받게되는데, 이것이
튜플 언패킹
(Tuple Unpacking) 이다. 이를 활용하여 하나의 함수로 여러개의 반환값을 갖도록 할 수 있고 그것들을 각각의 변수에 할당할 수 있다.
튜플 패킹은 여러개의 값을 하나의 변수에 담는 방법으로 다음과 같이 간단하게 할 수있다.
dt = [1, 2, 3, 4, 5] # 이렇게 리스트에 값들을 담는 대신
dt = 1, 2, 3, 4, 5 # 이렇게 값을 지정하면 튜플 형식으로 값을 담는다 >>>> (1,2,3,4,5)튜플을 사용할때 index 기반으로 참조하기 보다는 unpacking을 사용해 적절한 이름을 붙여준 뒤 사용하는것을 권장한다. (가독성이 매우 좋아진다). 다음과 같은 코드를 살펴보자.
# 가독성이 떨어지는 나쁜 예
student1 = (90, 80, 90)
print(student1[0], student1[1], student1[2]) # 90 80 90
# unpacking 을 적절히 사용한 좋은 예
student1 = (90, 80, 90)
kor, eng, math = student1
print(kor, end, math) # 90 80 90
#특정 원소만 취하고 싶은 경우
student1 = (90, 80, 90)
_, _, math = student1 # 수학 점수만 사용하겠다는 의지
print(math) # 90객체 정렬
객체를 정렬 하려면 리스트를 정렬할 때 이용했던 sort 함수를 이용하면 가능하지만 key 라는 인자에 정렬 기준을 정의 하는 함수를 넘겨줘야하며, 이때 사용하는 익명함수를 lambda 라고한다. lambda 함수는 다음과 같이 표현한다.
#보편적인 함수
def f(x):
return x * 2
print(f(3)) # 6
#lambda 함수
f = lambda x: x * 2
print(f(3)) # 6객체를 특정 기준에 따라 정렬 할 때는 이를 활용해 다음과 같은 방식으로 한다.
class Student:
def __init__(self, kor, eng, math):
self.kor = kor
self.eng = eng
self.math = math
students = [
Student(90, 80, 90), # 첫 번째 학생
Student(20, 80, 80), # 두 번째 학생
Student(90, 30, 60), # 세 번째 학생
Student(60, 10, 50), # 네 번째 학생
Student(80, 20, 10), # 다섯 번째 학생
]
students.sort(key=lambda x: x.kor) # 국어 점수 기준 오름차순 정렬
for student in students: # 정렬 이후의 결과 출력
print(student.kor, student.eng, student.math)
>> 20 80 80
60 10 50
80 20 10
90 80 90
90 30 60
students = [
Student(90, 80, 90), # 첫 번째 학생
Student(20, 80, 80), # 두 번째 학생
Student(90, 30, 60), # 세 번째 학생
Student(60, 10, 50), # 네 번째 학생
Student(80, 20, 10), # 다섯 번째 학생
]
students.sort(key=lambda x: -x.kor) # 국어 점수 기준 내림차순 정렬
for student in students: # 정렬 이후의 결과 출력
print(student.kor, student.eng, student.math)
>> 90 80 90
90 30 60
80 20 10
60 10 50
20 80 80Tuple 을 정렬할때도 lambda 함수를 이용 할 수 있다.
students = [
(90, 80, 90), # 첫 번째 학생
(20, 80, 80), # 두 번째 학생
(90, 30, 60), # 세 번째 학생
(60, 10, 50), # 네 번째 학생
(80, 20, 10), # 다섯 번째 학생
]
students.sort(key=lambda x: x[0]) # 국어 점수 기준 오름차순 정렬
for student in students: # 정렬 이후의 결과 출력
kor, eng, math = student
print(kor, eng, math)
>> 20 80 80
60 10 50
80 20 10
90 80 90
90 30 60
students = [
("lee", 80, 90), # 첫 번째 학생
("kim", 80, 80), # 두 번째 학생
("park", 30, 60), # 세 번째 학생
]
students.sort(key=lambda x: x[0]) # 이름 기준 사전순 정렬
for name, eng, math in students: # 정렬 이후의 결과 출력
print(name, eng, math)
>> kim 80 80
lee 80 90
park 30 60
여러 우선 순위를 갖는 객체 또는 튜플 정렬,즉 첫번째 우선순위 기준이 동일하여 두번째 우선순위 기준을 정해줄때, 는 다음과 같이 lambda 함수의 반환값을 튜플로 주면 된다.
class Student:
def __init__(self, kor, eng, math):
self.kor = kor
self.eng = eng
self.math = math
students = [
Student(90, 80, 90), # 첫 번째 학생
Student(20, 80, 80), # 두 번째 학생
Student(90, 30, 60), # 세 번째 학생
Student(60, 10, 50), # 네 번째 학생
Student(80, 20, 10), # 다섯 번째 학생
]
# 첫 번째 우선순위는 국어 점수 오름차순
# 국어 점수가 같다면 두 번째 우선순위는 영어 점수 오름차순
students.sort(key=lambda x: (x.kor, x.eng))
for student in students: # 정렬 이후의 결과 출력
print(student.kor, student.eng, student.math)
>> 20 80 80
60 10 50
80 20 10
90 30 60
90 80 90
# 만약 국어 점수를 오름차순으로 정렬하되, 국어 점수가 동일한 경우에는
# 영어 점수를 내림 차순으로 정렬하고 싶은 경우라면,
# 영어 점수만 내림차순이 되도록 다음과 같이 tuple을 **(x.kor, -x.eng)**로 설정해주면 된다.
정렬 기준이 매우 복잡한 객체 정렬
국어 점수를 기준으로 정렬하되, 국어 점수가 30의 배수인 경우가 먼저 나오도록 하는 식의 복잡한 기준을 갖는 정렬을 구현 할 때는 lambda 함수 대신 직접 기준을 정해주는 comparator 함수를 만들어줘야 한다. python3에서는 이 함수를 sort함수의 key 인자로 넘길때 꼭, functools내 cmp_to_key 함수를 import하여 cmp_to_key(compare) 식으로 감싸준다.
정렬의 기준을 나타내는 함수인 compare 함수에는 인자를 2개 설정해 준다. 이를 x, y라 한다면 x가 앞에 있는 원소, y가 뒤에 있는 원소라 가정했을 때 이 순서가 우리가 원하는 순서라면 0보다 작은 값을, 반대라면 0보다 큰 값을, 둘의 우선순위가 동일하다면 0을 반환하는 함수를 작성해줘야 한다. 이때 보통 반환값에 1, -1, 0을 사용한다.
from functools import cmp_to_key
students = [
Student(90, 80, 90), # 첫 번째 학생
Student(20, 80, 80), # 두 번째 학생
Student(90, 30, 60), # 세 번째 학생
Student(60, 10, 50), # 네 번째 학생
Student(80, 20, 10), # 다섯 번째 학생
]
# custom comparator를 직접 정의
# x가 앞에 있는 학생, y가 뒤에 있는 학생이라 가정했을 때
# 이 순서가 우리가 원하는 순서라면 0보다 작은 값을,
# 반대라면 0보다 큰 값을
# 둘의 우선순위가 동일하다면 0을 반환하면 됩니다.
# 보통 반환값에 1, -1, 0을 사용합니다.
def compare(x, y):
# x만 30의 배수라면 x가 더 앞에 있어야 하므로
# 현재 순서가 옳습니다.
if x.kor % 30 == 0 and y.kor % 30 != 0:
return -1
# y만 30의 배수라면 y가 더 앞에 있어야 하므로
# 현재 순서는 틀렸습니다.
if x.kor % 30 != 0 and y.kor % 30 == 0:
return 1
# 우선 순위가 동일한 경우입니다.
return 0
# 점수의 총합 기준 오름차순
students.sort(key=cmp_to_key(compare))
for student in students: # 정렬 이후의 결과 출력
print(student.kor, student.eng, student.math)
>> 90 80 90
90 30 60
60 10 50
20 80 80
80 20 10정렬된 숫자 위치 알아내기
양의 정수를 원소로 갖는 길이가 N인 수열이 입력으로 주어졌을때, 이 수열을 오름차순으로 정렬 했을 때 각각의 위치에 있던 원소가 어느 위치로 이동하는지 출력하는 코드를 작성하자.
Ex1:
입력:
7
3 1 6 2 7 30 1출력:
4 1 5 3 6 7 2코드:
n = int(input())
given_input = list(map(int, input().split()))
numbers = [(el, i) for i, el in enumerate(given_input)]
answer = [-1] * len(given_input)
numbers.sort(key=lambda x: (x[0], x[1]))
for i, number in enumerate(numbers):
answer[number[1]] = i + 1
for el in answer:
print(el,end=' ')
'TIL' 카테고리의 다른 글
| [TIL]20220529 (0) | 2022.05.29 |
|---|---|
| [TIL]20220528 (0) | 2022.05.29 |
| [TIL]20220526 (0) | 2022.05.26 |
| [TIL]20220525 (0) | 2022.05.25 |
| [TIL]20220524 (0) | 2022.05.24 |


